
Key Projects
Misleading News Headline Detection
In digital environments where information is shared online, news headlines play an essential role in the selection and diffusion of news articles. If the short text does not represent the main content correctly, it can be misleading and adversely affect the entire news reading experience. Therefore, we tackle the headline incongruity problem, in which a headline makes an irrelevant or opposite claim to the part of the main content. In particular, we implement deep learning models that detect the incongruity between a headline and a body text. Motivated by the innate hierarchical structure of news articles, we first design an attention-based hierarchical dual encoder that models a length news article through two-level recurrent neural networks. We further extend the hierarchical approach by a graph neural network where headlines and paragraphs are connected.
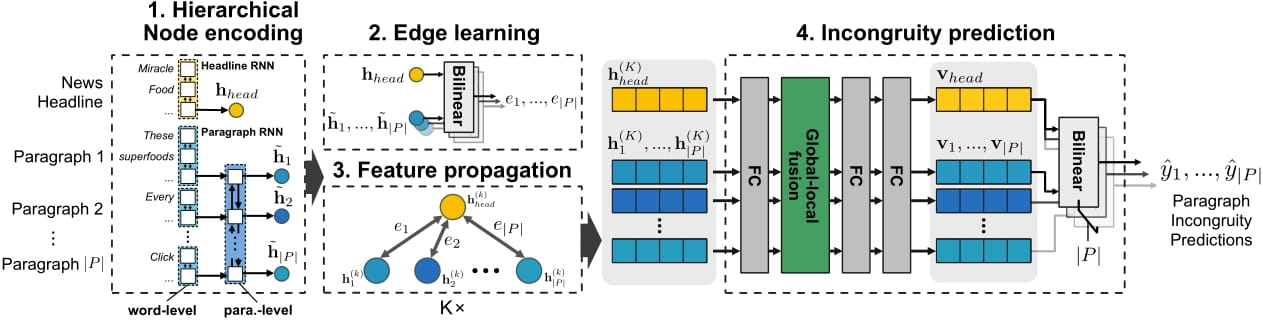
In order to convey the results of the machine learning model to potential readers in an effective manner, we implement BaitWatcher, a lightweight web interface that guides readers in estimating the likelihood of incongruence before clicking the headline (FNDM). You can watch a demonstration of the web interface in the following video.
Publications
- Learning to Detect Incongruence in News Headline and Body Text via a Graph Neural Network. In IEEE Access, 2021.
- Detecting incongruity between news headline and body text via a deep hierarchical encoder. In AAAI, 2019.
- BaitWatcher: A Lightweight Web Interface for the Detection of Incongruent News Headlines. In Springer Book Chapters on Disinformation, Misinformation, and Fake News in Social Media. 2020.